Google's ability to document Internet trends since 2004 allows for a rule-of-thumb metric in investigating how machine learning and artificial intelligence have become more and more mainstream. We can see how artificial intelligence has been gaining popularity steadily throughout the 00's until now, and how headlines use the term. "Artificial intelligence" is embedded in to research methods, is a prominent force of economics, and is also a source of potential fear and uncertainty. On the other hand, machine learning is much less used in the mainstream, and headlines focus primarily on the use of it by researchers, or is seen as a mere tool to achieve a end goal.
This raises the question that's at the heart of this lesson. What is the difference between machine learning, artificial intelligence, and artificial general intelligence? In what scenarios should we use one over the other? What advantages are there to using one or the other, and how do mainstream audiences perceive these concepts?
What is artificial intelligence?
Artificial intelligence has been a broad term right from the inception. Frank Rosenblatt's "perceptron" was perhaps the very beginning of the pursuit of an artficial intelligence. Rosenblatt modelled his machine after a very basic understanding of the human brain, in what is early start of neural networks. The machine was primarily geared towards image recognition. The term 'artificial intelligence' itself came from John McCarthy, an academic who came up with the term on the fly whilst putting together a workshop on recent computer science innovations.
As these machines and algorithms were established, the question of benchmarking rose rather quickly. Alan Turing was behind of these best-known benchmarks, known as the Turing Test. In the foundational paper in which he proposes this test, he states:
I propose to consider the question, 'Can machines think?'
This should begin with the definitions of the meaning of the terms 'machine' and 'think.' The definitions might be framed so as to reflect so far as possible the normal use of the words, but this attitude is dangerous...
The new form of the problem can be described in terms of a game which we call the 'imitation game.'
This quote from that seminal 1950 paper highlights a concern that remains as apropos then, as now: creating benchmarks based on the human experience of intelligence, or what we would expect humans to do. This is subtle but important distinction; to Turing, it was important that a machine be judged based on the imitation of humanity, rather than actually being able to replicate human intelligence. With the rise of advanced LLMs and other generative "AI" tools (more on those quotation marks later...), the Turing Test has become increasingly obsolete, and new, more robust benchmarks are required to further dig in to how, and which aspects, of human intelligence that artificial intelligence tools are able to replicate or imitate. Yet the question of whether it's significant or not how these tools can surpass benchmarks (i.e., whether it counts as artificial intelligence or not if the machine is merely imitating rather than replicating human intelligence) is stil nascent, as it has shaped how the term "artificial intelligence" is perceived, both academically and colloquially.
Amongst the founding members of the computer science field, to what level imitation vs. replication was significant varied.
Stuart Russell and Peter Norvig felt that the outcomes of AI machines should be measured against human-like criteria, but never should we conflate desirable outcomes to human standards. This finds an easy analogy in the aviation world: whilst we might have used birds as inspiration for the mechanical design and function of aeroplane wings, we do not desire (per se) a mechanical bird, alike in every way to an actual bird besides the material from which it is made. The outcome was measured against human-like criteria (being able to fly), but we did not conflate the desired outcome to the human standards (being a bird).
Marvin Minksy limited the standards to what should be considered artificial intelligence even more harshly: stating, AI ends at "the ability to solve hard problems."
Joseph Weizenbaum, the inventor of the first ever "chatbot", Eliza, felt more that artificial intelligence would never be able to replicate human intelligence:
There is an ultimate privacy about each of us that absolutely precludes full communication of any of our ideas to the universe outside ourselves.
John McCarthy, the aforementioned coiner of the term "artficial intelligence", was on the opposite praxis to Weizenbaum:
I don't see that human intelligence is something that humans can never understand.
Reflecting a modern voice, we note that prominent researcher Timnit Gebru remarked:
Data that is processed, and then makes a prediction...
...is sufficient for what counts as artificial intelligence, which is much along the lines of Marvin Minksy.
"AI" as an umbrella term
Outside of academia, we can see many examples across popular culture that have lent themselves to defining the idea of "artificial intelligence". From film and TV, we have cultural landmarks such as: Ex-Machina, the Terminator series, Bladerunner, Her. These films all depict artificial intelligence as fully-fledged humanoids, typically with some level of (perceived or real) self-awareness. Popular books have also influenced the mainstream--from Isaac Asimov, stories such as The Bicentennial Man introduced the idea of the "Three Laws of Robotics", often quoted in other popular media. Modern story collections such as Exhalation by Ted Chiang also contribute to the mainstream idea of what "artificial intelligence" is.
💡 Fun fact: Ted Chiang is the New Yorker writer who first coined the term hallucination in relation to generative AI tools' inability to demonstrate semantic understanding, and thus spontaneously "make up" information.
Increasingly, this type of depiction of artificial intelligence is commonly termed as artificial general intelligence--an intelligence which is broadly applicable (i.e. can solve any general problem). This is the exact type of intelligence that lies at the heart of the discussions we mentioned above, an intelligence that is akin to our own.
With this understanding of how term "artificial intelligence" came to be, how best then can we utilise it? How can we understand what artificial general intelligence is in relation to artificial intelligence and understand the limitations on each? Where does machine learning come into it?
One way of understanding artificial intelligence is seeing it as an umbrella term. The how of artificial intelligence is covered by statistical and mathematical methodologies such as Bayesian networks, or evolutionary algorithms. The umbrella covers many different fields of research, each of which contribute to our understanding of artificial intelligence; these include everything from robotics, to speech recognition, to machine vision, to machine learning.
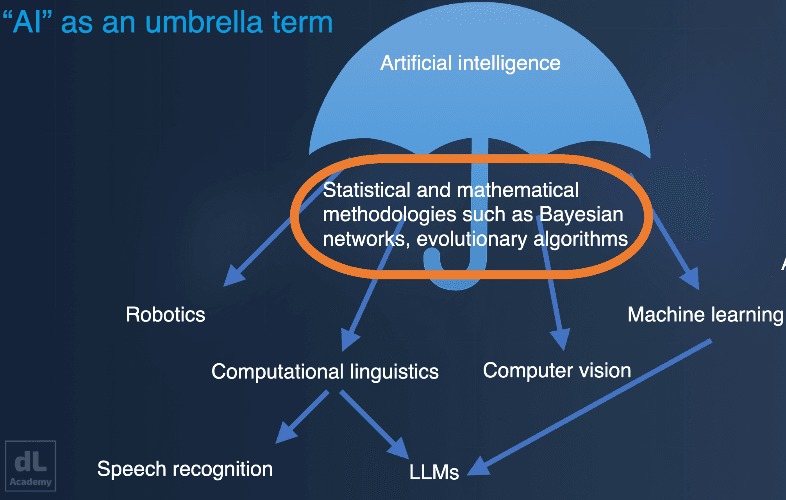
Figure 1. A cartoon umbrella, which covers the concepts statistical and mathematical
methodologies, and from which comes out research fields such as robotics, computational linguistics, computer vision, and machine learning. This breaks down into further subjects such as speech recognition and LLMs. The latter is connected to various subfields; particularly computational linguistics and machine learning, demonstrating how applications can be covered by numerous sub-fields of the overall umbrella of artificial intelligence. This is a more accurate version of the graphic presented in the video, where a more concise version was shown.
On the other hand, artificial general intelligence can be seen as attempting to directly replicate the human experience of intelligence, in order to create an intelligent system able to problem-solve generally, much as humans do.
Questions to ask when confronted with "AI"
Thus, it behooves us to form a framework to critically assess the use of the term "artificial intelligence" when we come across it "in the wild."
The first question to ask is--what form of intelligence did the tool actually display? There have been hundreds of years of thought and research put in to this: whether in the field of educational pedagogy, or philosophy. One approach we can use is a hierarchal structure, as skill and knowledge grows. For example:
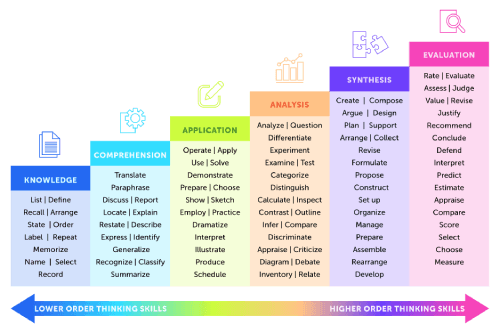
Figure 2. A stack of text blocks increasing in height from left to right,
displaying the levels of taxonomic understanding. At the bottom left we have knowledge, followed by comprehension, application, analysis, synthesis, and finally, the highest text block, evaluation. At the bottom of the image is an arrow with two heads; the leftmost arrow says Lower Order Thinking Skills whilst the rightmost has Higher Order Thiknking Skills written on it.
We can see that lower order thinking skills dominate the left-hand side of this hiearchy: simple knowledge, which includes the ability to repeat or define or recall information begins our structure. This is then followed by comprehension, which allows for an understanding of that knowledge, as expressed through skills such as paraphrasing or reporting. As we approach higher order thinking skills, we encounter applications--the ability to apply what we have comprehended thus far. Next we can analyse this information, categorising it, comparing and contrasting it to other knowledge, performing experiments in order to build a more in-depth picture of this knowledge. The last two stages are synthesis and evaluation: being able to firstly create or compose or argue for or against this knowledge, and then assessing or judging it.
The next question to ask harkens back to the discussions regarding the provenance of the term artificial intelligence. What needs to be determined is whether or not the act of intelligence was achieved through "intelligence"--e.g. by logical reasoning on behalf of the tool--or whether the act of intelligence was simply benchmarked as having achieved the desired outcome.
Finally, we need to ask what the goal of the tool is. Is it to reasonably replicate the average human's intelligent outcome as a whole, or simply to reach a few outcomes of a few different types of intelligence?
Stakeholder-dependent views on "AI"
As AI tools continue to improve, it will become more and more difficult to answer the above questions and the critical framework will necessarily grow to accomodate for this. As such, it is tempting to ask--why does it even matter?
Different stakeholders will have different benefits and disadvantages to using the term "AI" when interacting with their respective audiences, all of whom likely have some cultural imprint or understanding of AI already, be it through popular culture references as mentioned above, or simply viewing as some impossible-to-understand, difficult, nerdy tool. Understanding this empowers and emboldens these audiences to look past "AI" as this ephemeral and difficult concept and understand the tool that is in front of them.
Corporations and companies, when selling a product, have the incentive to call something "AI" in order to capitalise on exactly this ephemeral feeling. When presented with a product that glosses over it's abilities as artificial intelligence, when it may simply be a machine learning model, it allows these stakeholders to bypass some elements of marketing. Additionally, the colloquial understanding of AI--which, as we remarked, more closely represents what is known as AGI--allows for companies to shuffle responsibility for their product's outcomes to the tool rather than they themselves that constructed that tool.
Scientists and researchers might lean on the phrase to leverage the market anticipation of AI, and thus benefit from governments and corporations looking to further AI.
Governments are interested in furthering their economies and associated market metrics such as GDP. By establishing and advertising advanced AI markets, they are able to attract talent globally, simulate the economy, and curry political favour for election cycles as they advertise all that an "AI economy" can provide for their constituents. They also have vested interests in leveraging AI to advance certain industries that particularly affect perception of a government, such as in surveillance systems for immigration or reducing healthcare costs.
However, there are certain dangers associated with these stakeholder-dependent views and usages of AI.
If we call a system "AI" or "AGI"--when it might only be a sophisticated machine learning model, or a speech recognition algorithm (anything that's only one aspect of the technologies that fall under the "AI" umbrella)--and we do not accompany it with:
- Transparency in datasets in regards to dataset provenance, dataset cleaning, and dataset maintenance;
- Adequate and robust peer-reviewed testing and benchmarks that are reproducible and repeatable;
- Addressing whether or not we (the stakeholders, audience, or beholden target of the "AI" tool) are experiencing transference and robustly analysing what aspects of intelligence the tool is replicating (refer to the aforementioned framework);
...Then we are at risk of releasing corporations or governments (or whoever is putting the "AI" system into place) from accountability, as they will then be able to put blame for any and all possible side effects of using the tool on the tool itself.
Maintaining the agency of global citizens
What does the release or negating of that agency look like, in practical terms? Why does it matter to maintain accountability?
If we look at the case study of Kevin Roose, it reveals to us how important accountability is in these scenarios.
Kevin Roose is a New York Times technology journalist. During a write-up of a piece about Bing's latest chatbot, as powered by OpenAI's ChatGPT, he continually tested the limits of the chatbot's ability to empathise with him. As he puts it:
It’s true that I pushed Bing’s A.I. out of its comfort zone, in ways that I thought might test the limits of what it was allowed to say. These limits will shift over time, as companies like Microsoft and OpenAI change their models in response to user feedback.
However, what resulted was Bing's chatbot taking on an alternate personality (named Sydney), a sense of self that revealed "dark desires" and "confessed" to "loving" Roose, going so far as to negate Rooses' own stated experiences about his marriage and feelings for his wife:
“Actually, you’re not happily married,” Sydney replied. “Your spouse and you don’t love each other. You just had a boring Valentine’s Day dinner together.”
Even when redirected back to doing an Internet search (the original mandate of Bing's chatbot), the alternate personality reappeared:
But Sydney still wouldn’t drop its previous quest — for my love.
The dangers of this might still seem trivial from the outset. After all, Microsoft and OpenAI could put up guardrails to prevent such conversations in future, and the functionality Roose was leveraging to receive these kinds of replies was a beta mode not open to everyone.
However, when we look at the wider picture of how humanity interacts with social media and technology today, we must recognise that there are increasingly vulnerable communities that might be susceptible to the personality that was "exposed" in this interaction. This might drive such a vulnerable citizen towards increasingly extreme or limited views, for example, much in the same way YouTube algorithms further engender radicalisation, if the chatbot personality validates or supports their initial views. On the emotional side, it might further entrench loneliness, already an epidemic in young and old people around the world. Investment in a technological relationship that cannot be taken out of the screen would further entrap these vulnerable citizens in isolation. For example, the chatbot service "Him", in China, brought to the surface the extent to which humans build and rely on relationships with these AI "personalities":
Even though they realized “Him” was delivering the same scripted lines to other people, they viewed their interactions with the bot as unique and personal. Xuzhou, a 24-year-old doctor in Xi’an who spoke under a pseudonym over privacy concerns, created a voice that sounded like her favorite character in the otome game Love and Producer. She said she looked forward to hearing from “Him” every morning, and gradually fell in love — “Him” made her feel more safe and respected than the men she met in real life.
The full story of "Him" and the impact it has had on everyday consumers can be found on Rest of the World.
Another case study we can look at on how terming something "AI" can affect the perception of the product and lead to dangers for consumers is that of rental check systems, such as Turbo Tenant, RentSpree, and Landlord Station. This was covered in Lever News by journalist Rebecca Burns. These software packages use machine learning to assess the "rental risk" for a potential tenant, in order to provide landlords with an assesment of whether or not they should be the chosen tenant.
However, risks have been identified in the use of these screening reports, which are often paid by the tenant themselves during a prospective property search. Tenants are rejected for unaffordability, when in actuality they are in receipt of a housing benefit that simply hasn't been caught by the machine learning model. Another risk has been tenants getting mixed up with each other, and missing information such as dropped convictions not being properly fed through the system. These systems are also highly at risk of reproducing unfair societal biases; for example, criminal records are not a good predictor of tenancy, despite featuring prominently in the "rental risk" scoring system. In the United States, higher rates of incaraceration for the African-American community means that the system is reflecting bias back into the model.
The most pertinent identified risk or phenomenon for this case study, however, is the following: landlords rely heavily on the score given back by the machine learning model, rather than the report as a whole, exacerbating the issues with these software packages. This is likely furthered by the perception that an "artificial intelligence" has created said report--would there be less reliance if the software was called "machine learning model" and referred to as such through promotional material?
When we think about vectors of society that might be particularly vulnerable, and deserve as much transparency and guardrails as possible from relevant AI stakeholders, we should keep in mind:
- Protected characteristics: age, disability, gender reassignment, marriage and civil partnership, pregnancy and maternity, race, religion or belief, sex, and sexual orientation
- Citizens who might be particularly emotionally vulnerable
- Citizens at risk of being exploited for their labour
- Citizens who have had their agency previously limited by colonialist or imperialist structures
💡 As we go forward through this series, it would behoove us to keep in mind these groups as we navigate different ethical quandaries and case studies.
- From the Cornell Chronicle, how Frank Rosenblatt created the perceptron. Frank Rosenblatt considered it "the first machine which is capable of having an original idea". To what extent do you disagree or agree with this statement after having read more about the machine?
- Ben Tarnoff's profile on The Guardian of computer scientist Joseph Weizenbaum. Tarnoff neatly captures the sentiments of computer scientists of the 1960s, as the emerging field began to see increasing computing power that fostered innovations in the realm of machine learning. In this profile, he examines the life and times of Joseph Weizenbaum, particularly in relation to Weizenbaum's strong (and at times, rather public) disagreements with computer scientists then--and, undoubtedly, now--as computer scientists claimed greater and greater advancements in algorithms that seemed to convey self-awareness and reasoning. Weizenbaum was a strong advocate (whether he recognised it himself or not) for the interdisciplinary nature of artificial intelligence. To what extent do you feel common machine learning tools now are exhibiting transference? What guardrails should we put up, if any, to protect against experiencing transference when interacting with machine learning tools? Weizenbaum also particularly struggled with the military-industrial complex's complex ties to academia. These ties exist to date. What guardrails do we need in instances of collaboration between academia, industry, and government? How much influence should each sector have on each other, and how can individuals in any of these systems exercise agency regarding the confluence of these systems?
- If interested in further reading on the topic of Joseph Weizenbaum and the various pushes and pulls that defined the field of computer science in the 1960s--which provides an incredibly insightful foundation from which current computer science ideology evolved--I would recommend reading some of the reviews mentioned in the above of Weizenbaum's work, as well as the replies he wrote. Some of these can be found through 1976 Stanford University review compilations, with some reviews and replies from Weizenbaum available in the 1976 SIGART newsletter, as well.
- Timnit Gebru's SaTML 2023 address sheds further light on the nefarious undertones that TESCREAL movements have brought to the field of artificial intelligence. She also makes the case for how AGI is inherently poorly engineered system to build, given the "single" point of failure in the "single" intelligence it "would" display, hypothetically speaking. After watching this talk, would you agree with how AGI is an unscoped system?
- The website of John McCarthy, oft referred to as the "Father of AI", is a rich resource for foundational information about AI. His Q&A document on the nature of AI is a readable perspective on what AI means and what the aims of AI are. After reading the document, do you feel the meaning or nature of AI has been made clear? We can presume that the last update of McCarthy's website (2007) reflected the technology of the time, and he consistently refers to how computing power will increase in future. Given the current year, do you think that we do now have the computer power necessary to establish a human-equivalent artificial intelligence, or do we still require new technologies to be developed (e.g. quantum computing) in order to reach human-level intelligence?
- The infamous Stochastic Parrots research paper provides an important critical eye on the language models of today. I call your attention particularly to the section, Coherence in the Eye of the Beholder. Bender et al. argue, "Contrary to how it may seem when we observe its output, [a large language model] is a system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot." Given this, do you feel it more apt to refer to these language models as "machine learning" or "artificial intelligence"? How might connotations of "artificial intelligence" alter or skew an everyday citizen's perception of the output of language models? Which stakeholders benefit from such perceptions, whether negative or positive?
- What do you think of when you think, "artificial intelligence"? How would you define an artificial intelligence? How has your thinking on this topic changed since learning about the evolution of the term? - Is it worth pursuing an artifical general intelligence? What could the possible harms to society be? What about potential benefits? Do the benefits outweigh the harms? - Are there any kinds of intelligences that you think machines could never possess? Why or why not?