Welcome to the forth section of the course. In this section we shall tackle the short-comings of the humble decision tree by introducing a new class of models: ensemble methods. The key idea is to take collections of "weak" machine learning models and build an aggregate model in a statistically rigorous way.
In this section, we shall explore the most popular prototype: a random forest. In this case, the weak learners are small decision tress which act together, democratically, to make robust and generalisable predictions.
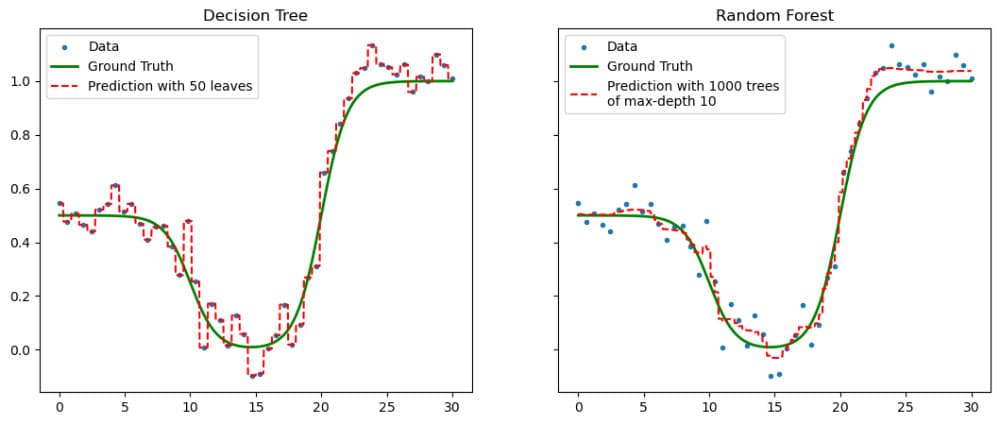
Figure 1. Compare of the performance of a decision tree (left) with a random forest of decision trees (right).
We shall cover:
- Introduction to the notion of ensemble models.
- Key concepts and terminology.
- Worked data examples: Random Forests.
- Performative comparison with a single decision tree.