- Have included a new genre of algorithm in your machine learning toolkit: tree-based ensemble models.
- Have an understanding of the core concepts underpinning decision trees, statistical ensemble methods, and accelerated gradient boosting.
- Be able to interpret these models in different scenarios to explain your results and understand performance.
- Understand how and when to select non-parametric (flexible/agnostic) machine learning models over parametric (or pre-specified) models.
In this course, we'll broaden our predictive ability and embark on an exploration of tree based algorithms. These algorithms are entirely data driven; the functional form of their outputs is not controlled, nor its properties, by user choices. Decision trees really do 'learn'.
And so shall we. In this course we'll start with the humble decision tree, a rather delicate model, and progress to the mighty ensemble models: random forests and gradient boosted trees. Gleaning fundamental understanding of the algorithms from a standalone tree, we shall deploy ever more robust algorithms with a good understanding of their operation and tuning parameters.
These are important concepts and techniques for any professional machine-learning toolkit as they constitute some of the state-of-the-art models used by machine learning practitioners today.
In this course, you will get to grips with:
-
Non-parametric tree-based models, and develop an understanding of when such a flexible tool can be deployed in a robust way, avoiding over, and indeed under-fitting.
-
Implementing and tuning advanced ensemble machine-learning techniques with detailed code walk-throughs.
-
The theoretical structure of each of the algorithms, from the baseline decision tree through the statistical generality of ensemble models.
-
How these algorithms may be deployed into a machine learning project with the latest and state-of-the-art packages and tools.
This course contributes neatly to our series on developing professional machine learning tools; see our first foray into non-parametric modelling in The Kernel Trick: A first look at flexible machine learning. In this course, we build upon this foundation over the following three sections:
Section 1: Branch Out With Decision Trees.
If we want machines to think, shouldn't we apply some introspection first? How do we sift through information and make decisions? Consider a simple decision: "I'll cycle tomorrow, but only if the forecast is 60% likely to be dry". Based on what data? Weather forecasts. We choose our threshold (60%) and act accordingly in one of two ways. Of course, once taking the cycling option one may have many more decisions to make. What you'll see in this section is that a machine that can think in this way can very quickly and easily find optimal choices among a vast amount of data.
This is the basis of (dare I say "roots of") a decision tree. In this section, we shall unearth the mechanism by which they work and demonstrate their utility on a variety of problems. We'll discuss their pros and cons. Importantly, these simple models can be used as components of very effective models described in the next sections.
Section 2: Democracy Amongst Models with Ensembles.
When machine learning models such as the decision tree act alone they are vulnerable to overfitting to the original data they are shown. We know from experience that a fresh pair of eyes on a problem can help give new insight. So why not introduce more machine learning models to help each other out: an ensemble.
But how can ensembles of models give sensible predictions? How do we encode democracy? And, crucially, how can we deploy this technique to reduce over-fitting and improve model generalisation?
We shall answer these questions throughout this section whilst focussing on a typical ensemble technique: Random forests.
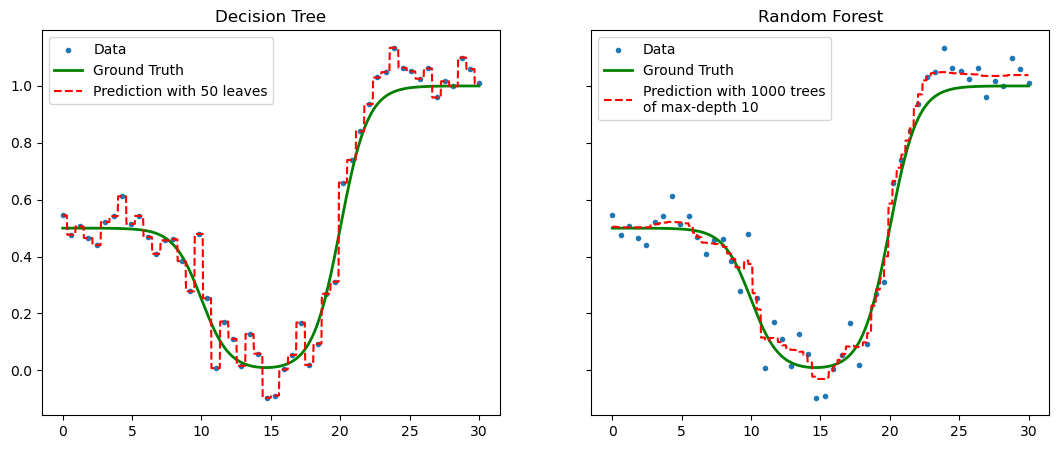
Figure 1. Overfitting in a decision tree can be interpolated by deploying a random forest.
Section 3: Give Yourself a Gradient Boost.
Ensembles act as vast populations of independent models which participate in a democratic process to make advanced predictions.
But what if a collection of models all worked together from the start? One such technique, the jewel in the crown of our course, is known as 'Gradient Boosting'. Instead of all models predicting the target, each learns the error given in the previous. This means we can use far smaller models all working toward a common goal: reducing the error in our system.
In practice, this technique frequently outperforms all others. Perhaps the most successful tool in our toolbox is an advanced application of gradient boosting: XGBoost. In this section, we shall explore the ins and outs of gradient boosting as a technique as well as the application of XGBoost in the wild.
🤖 Use AI to help you learn!
All digiLab Academy subscribers have access to an embedded AI tutor! This is great for...
- Helping to clarify concepts and ideas that you don't fully understand after completing a lesson.
- Explaining the code and algorithms covered during a lesson in more detail.
- Generating additional examples of whatever is covered in a lesson.
- Getting immediate feedback and support around the clock...when your course tutor is asleep!